ZRobot 乔杨:如何证明你是你?
by 清华金融评论 2019-07-18 10:41:34
2019年7月12日-7月14日,2019第四届全球人工智能与机器人峰会(CCF-GAIR 2019)于深圳正式召开。ZRobot CEO乔杨在AI+金融专场发表了《数字科技驱动的信贷反欺诈技术》的主题演讲。本文根据其演讲内容整理。

我今天分享的主题是“数字科技驱动的信贷反欺诈技术”,关于AI、数据挖掘技术、模型算法在这个领域的应用和尝试。
首先介绍一下我们公司。我们成立于2016年10月,成立之初的目的是利用海量高维的数据资源,结合行业内最先进的数据挖掘技术和模型算法,借助京东数科丰富的实践应用场景,不断打磨自身的技术实力,同时赋能合作伙伴,帮助他们提升自身的风控实力和运营效率。目前已经和众多的银行、保险、证券、信托、小贷公司、持牌消金以及融资租赁公司等等展开合作,为他们提供了各类的产品支持以及智能风控、智能营销解决方案,合作的机构近300家。
今天讲的是,我们在反欺诈领域究竟做了哪些尝试。
一、欺诈性案件背后的真相
大家经常会在媒体上看到一些跟欺诈相关的令人触目惊心的新闻报道,例如医美中介欺诈、黑中介骗贷、洗钱套现等等。随着中国消费信贷及互联网化的飞速发展,信贷产品种类的日益丰富,欺诈的手段也不断在更新进化。欺诈分子是一群高智商且勤奋努力的人群,加上欺诈防范手段的滞后性,使得欺诈案件层出不穷,可谓道高一尺,魔高一丈。从早期的传统欺诈手段,已经逐步进化为更加先进更难察觉的新型欺诈手段,比如早期的利诱员工到如今的潜入机构,本人申请到资信包装等等。欺诈领域经常存在一种“道高一尺,魔高一丈”的情况,要怎么做才能实现“魔高一尺,道高一丈”,真正实现欺诈的有效防范?

风控从业者都知道,在信贷风险领域,我们最关注的是信用风险和欺诈风险。信用风险非常好理解,最多的是从还款能力和意愿这两个大维度去判断。但是在欺诈风险领域,更多关注的是一方、二方、三方和多方混合欺诈,这就使得欺诈风险在判断上更加复杂,难度更加大。

由于中国移动互联网的发展,比欧美一些国家更加快速、更加发达,使得欺诈手段层出不穷,也使得我们在这个领域反欺诈的技术相对滞后。在美国,欺诈损失比例不到20%,而在中国为50%甚至更高。所以在中国,整体信贷环境更加恶劣,防范欺诈风险的重要性更高。在建模方式上,我们通常是以已知的欺诈案件库进行定义,再进行反欺诈模型的搭建,本身就很难进行有效的提前预警。
举个例子,当时我在美国做反欺诈的时候,有一个客户在拉斯维加斯的线下BestBuy(百思买)门店买了一部液晶电视,买完之后到周围的麦当劳Drive-Through买了一个汉堡。我们的交易反欺诈模型是实时在线上跑的,用户每做一笔刷卡,系统都在计算是否可以通过。这个用户平时是经常在线上消费的,很少有在线下大额消费的行为,所以这笔交易被定义为高度欺诈嫌疑的交易。使得这个用户在买麦当劳汉堡的时候,他的交易就被拒绝了。这个用户打电话进行投诉,他说:“如果你怀疑我是一个欺诈分子,为什么不在我买电视的时候把我的交易拒绝?而是在我购买2块钱汉堡的时候拒绝?”——这就说明我们的模型是存在一定滞后性的。
二、如何预防欺诈
对于不同的欺诈类型,我们需要从三个维度进行考虑:了解客户、了解员工以及了解对手。
但欺诈风险的防范必须了解所有交易参与对象,不然就会有疏漏,比如我们只去了解员工和对手,就会遗漏第一方欺诈的风险;只了解客户和员工,就会给黑产、团伙欺诈等第三方欺诈以机会。
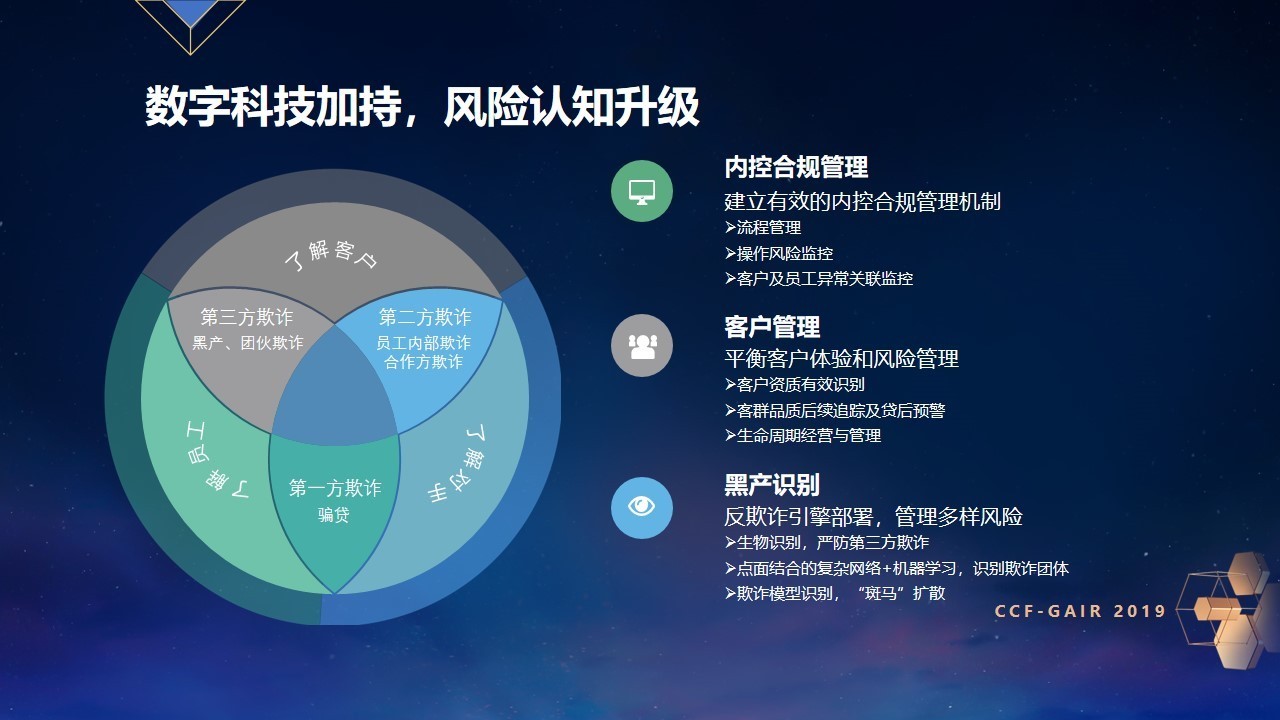
右边不同的颜色是对应不同欺诈类型的防范措施,比如建立完善的内控合规制度可以有效防范员工内部欺诈。但黑产识别是反欺诈领域最为关键的环节,在这个环节ZRobot进行了大量的尝试和探索,我们认为通过生物识别技术、点面结合的复杂网络+机器学习技术(我们称之为“漫网技术”)以及欺诈模型识别,尤其是我们提出的“斑马”扩散技术是三方欺诈的最为有效的防范手段。
具体是什么原因呢?
首先,反欺诈的核心是证明交易对手是客户本人,这是第一步,也是最关键的一步。中国移动互联网的高度发展,给了很多金融机构在前端非常有效的工具,用来和用户交互,同时抓取有效的数据节点。比如说现在非常成熟的移动APP,前端可以抓取的用户标签已经多达200多个。在此基础上做一些特征的延伸,是非常有想象空间的。通过轻量级的前端SDK生物探针部署,捕捉用户多维度的生物行为并在云端进行实时计算判断,同时结合传统的人脸、指纹及声纹识别,就可以在保障客户体验的同时达到欺诈风险防范的目的。这样的方式具备的优势非常明显,比如无需硬件支持,验证过程无感知,无需用户主动配合,可进行连续判断,同时可实现实时风险决策。随着欺诈手段的不断升级,欺诈的团伙化特征也日益明显,欺诈的上下游产业链也越来越庞大,越来越成熟。仅仅通过对个人的欺诈风险判断不能防范团伙作案带来的影响和损失。
我们提出的漫网技术有效的解决了这个问题:类似谷歌提出的Graph Learning(图形学习), 对用户全方位的关联关系进行识别包括设备关联,通信关联等等,构建用户的关系网络图谱,通过无监督算法将无差别用户划分为不同群组,同时针对关联关系强弱进行判断设定权重。漫网的优点非常明显,在反欺诈领域已经取得了显著的效果。反欺诈中建模的流程和关注点,与传统信用模型相比,欺诈模型构建存在很大的挑战:基于业务知识及丰富的案件识别能力判断哪些交易定性为欺诈交易。有了稳定的案件库和欺诈数据标签之后,用作目标定义。特征工程设计的数据量及运算量大,近实时的数据挖掘包括浏览数据、网络行为挖掘、网络借贷、同一时间内的设备环境特征等等。由于欺诈手段方法更具多样性,而信用风险主要来自还款能力和还款意愿,比较具象,所以设计多特征多子模型的融合,同时模型的更新迭代必须跟得上欺诈环境的变化,所以模型部署也要考虑到这个问题,比如高频定期的模型效果监控,如何建立自适应模型等等。
三、我们做了哪些尝试和探索呢?
在这个领域我们做了哪些尝试和探索呢?
在电商领域,用户会在页面留下大量触点,比如点击浏览不同层次页面,但几乎所有深层次页面都会到SKU(库存进出计量的单位)或单品页面,所以我们提出了item2vector概念,类似文本挖掘领域的text2vector或word2vector,将文本分类为向量矩阵,比如高频低频文本,然后进行情感分析、语义分析等等。所以我们是将电商领域的item抽出,把用户浏览路径转换为向量形式,就可以用向量来描述一个用户在一个浏览session(会话控制)当中对哪些品类或单品产生浏览记录。由于浏览是有时间顺序的,所以我们将整个页面浏览时间顺序和向量放入卷积神经网络模型中加工训练特征,通过RNN(递归神经网络)方式我们提炼了大量原本通过人类业务经验或其他构建特征方法所不能提炼的特征。这些特征做为机器学习模型训练特征可大幅提升模型效果。这是我们对于深度学习方面的突破,有了这一理论基础,以及我们对于整个用户画像标签的深度挖掘能力,就可以把自身积累的经验对外进行赋能。
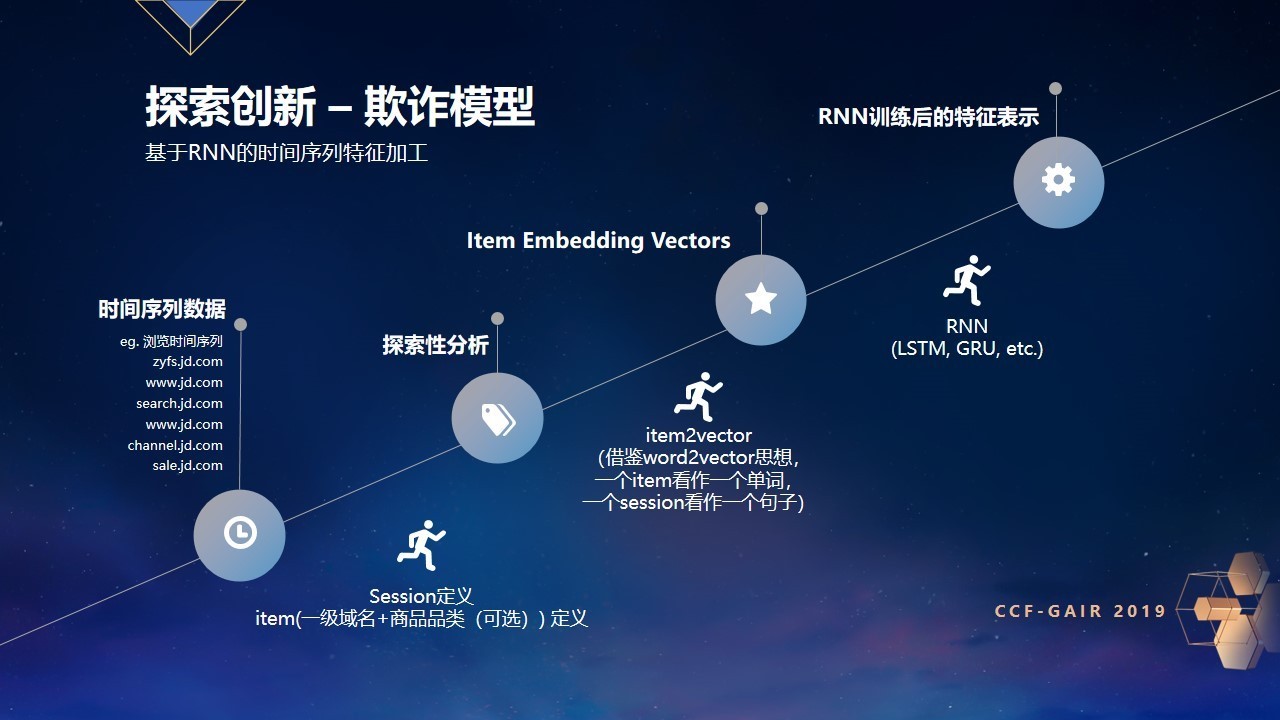
另外,我们聊一下RNN(循环神经网络)和LSTM(长短期记忆网络)的概念。RNN的输入维度为样本数量, 时间序列数,每个时间序列点的维度数量,输出维度可根据不同的应用场景在1个或多个序列时间点输出不同维度的结果;如图所示从X0至XT共T+1个时间点,每个时间点的维度可以为一个多维的向量。
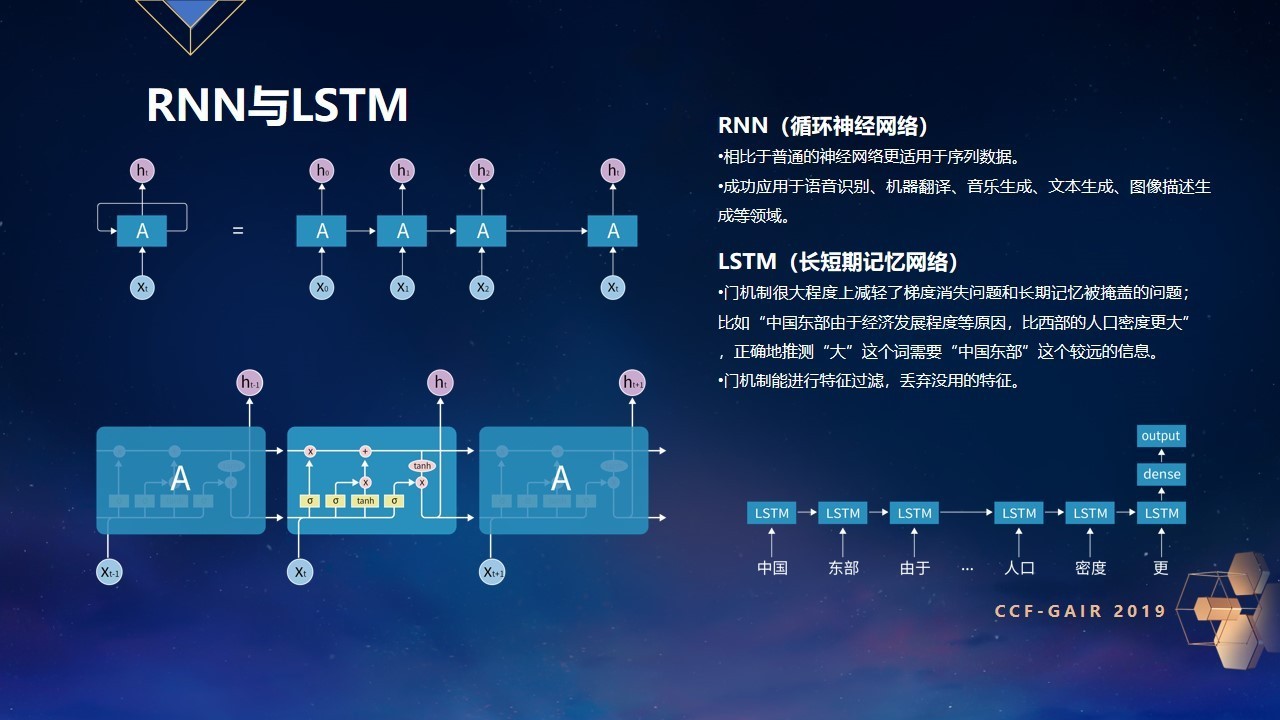
但在序列长度很长时,RNN会存在梯度消失和长期记忆被掩盖等问题,LSTM在每一个单元里面加入了门的机制,用于决定上一个单元信息和本单元新输入的信息多大程度的输入到本单元,以及多大程度地输出到下一个单元,有效解决了以上问题,同时能有效过滤无用特征。
具体是怎么应用呢?举个例子:下方左图是基于地理位置轨迹的数据样例,主要包含不同设备在不同时点驻留的位置经纬度、位置类型、驻留分类等。经过一系列数据清洗和特征加工得到完备的特征集合。然后经过序列截断、padding、特征标准化、reshape等流程进入LSTM模型。左下角是我们使用到的一个LSTM神经网络结构样例,经过LSTM LAYER(含一个MASK LAYER),最终经过2个dense layer得到输出结果。

通过这样的建模方式在训练集上到底取得了什么效果?基于上述数据和模型,最终我们在测试集上评估效果,单基于如上地理位置驻留数据,经过清洗、加工和建模,最终在我们的风险模型中KS能达到0.23,KS图和按照预测出来的分数等分10组在测试集上的lift值如下图所示,效果是非常明显的。
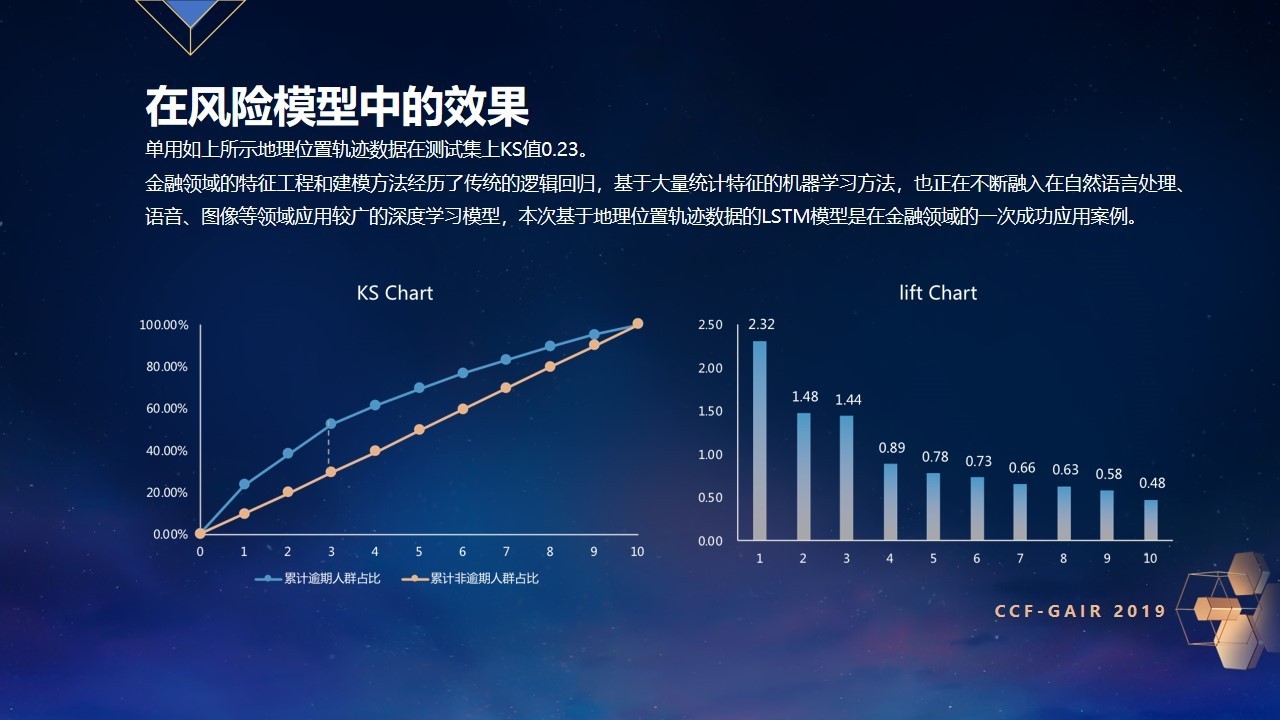
金融领域的特征工程和建模方法经历了传统的逻辑回归,基于大量统计特征的机器学习方法也正在不断融入在自然语言处理、语音、图像等领域应用较广的深度学习模型,刚刚展示的基于地理位置轨迹数据的LSTM模型是在金融领域的一次成功的应用。大家可以质疑这只是一个理论的测试集上的模型结果,那么实际应用中到底有没有好的表现呢?在我们内部的实际数据上,刚才这个建模方式用到实际的风险中,用打出来的欺诈评分,把识别的人群进行了分组,欺诈评分最高的组可识别出来的欺诈人群的欺诈率已经接近了平均比例的4倍。而最低的一组只有平均比例的0.05,所以接受前20%就可以把欺诈率降低一半,这就是实际运用的效果。

中国有一句古话叫做“近朱者赤,近墨者黑”,我们通常用的关联关系都是在黑的领域进行扩散,在已知的欺诈群体或者是用户至上进行关联关系的扩散,把周围的高危的群落识别出来,同样的概念可以适用到白的这批用户上。所以我们提出的概念是不仅要关注黑,更要服务好白,因为已知的信用度很高,非常优质的客户,跟他们的关系非常紧密的这群人,极大概率上也是一批非常优质的客户,或者是你的潜在优质客户。把这个概念应用到额外授信、精准营销领域,也可以取得非常好的效果。尤其是现在获客成本高居不下,这种技术带来的前景是非常大的。

刚才我说了欺诈评分可以有效把高危人群识别出来,前面提到的斑马扩散技术,通过网络扩散的方式,是可以把极端的人群作为有效的补充,更好地识别高危和低危的人群。实际效果如何?通过扩散出来的人群前14%,欺诈比例为平均水平的3.3倍,最后的13%只有平均水平的0.3倍,因为他们选取的维度不一样,因此可以结合我刚才说的建模方式做出的欺诈评分,可以更加有效的把这批高危和优质客户识别出来。
最后我也希望行业人士能够在业内和我们做更多的交流,大家联手在整个金融科技领域做出更多的贡献,谢谢大家。
(文章来源:ZRobot)